

TL;DR
Web scraping stock market data involves using Python and libraries like BeautifulSoup to extract financial information from websites such as Yahoo Finance. This process includes choosing a data source, parsing HTML or JSON, and saving the data for analysis.
By selecting the right tools and sources, you can efficiently gather the stock data you need.
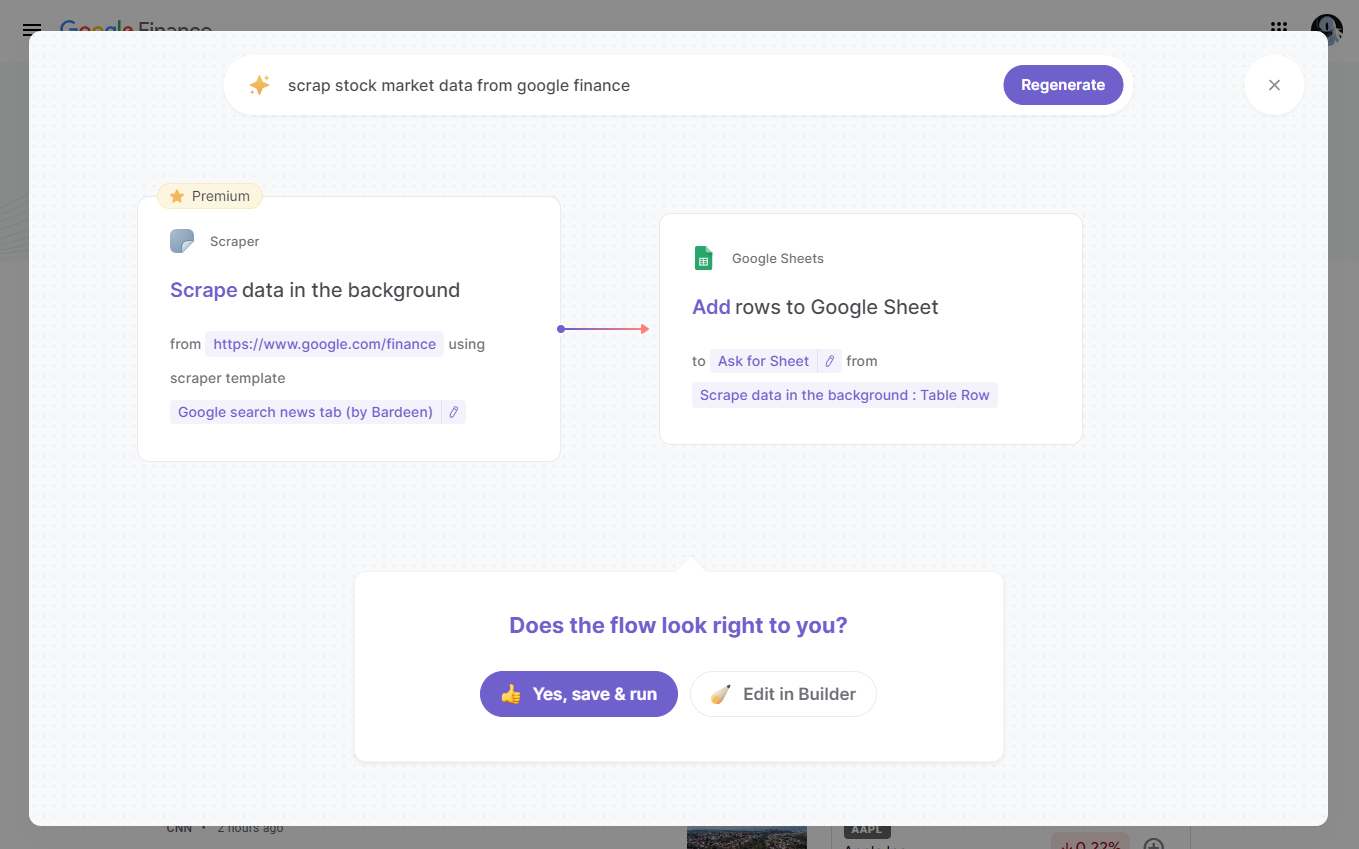
Automate this process and save time with Bardeen's powerful Scraper integration.
Web scraping is a powerful technique for extracting data from websites, and it's particularly useful for gathering stock market data. In this step-by-step guide, we'll walk you through the process of web scraping stock market data using Python. We'll cover setting up your environment, understanding legal considerations, identifying reliable data sources, automating data extraction, and storing and utilizing the scraped data effectively.
Setting Up Your Python Environment for Web Scraping
Before diving into web scraping stock market data, it's essential to set up your Python environment properly. Here's what you need to do:
.png)
- Install Python on your computer if you haven't already. We recommend using Python 3.x.
- Set up a virtual environment to keep your project's dependencies isolated. You can use tools like virtualenv or conda for this purpose.
- Install the necessary Python libraries for web scraping, such as BeautifulSoup and requests. You can install them using pip, the Python package manager.
Here's an example of how to install BeautifulSoup and requests:
pip install beautifulsoup4 requests
.png)
By setting up a dedicated virtual environment and installing the required libraries, you'll have a clean and organized setup for your web scraping project.
Understanding the Legalities of Web Scraping Stock Data
Before diving into the technical aspects of web scraping stock market data, it's crucial to understand the legal considerations and ethical implications involved. While web scraping itself is not illegal, the manner in which you scrape data and how you use it can raise legal concerns.
When scraping financial websites, pay close attention to their terms of service and robots.txt files. These documents outline the website's policies regarding automated data collection. Violating these terms can lead to legal consequences.
Some key points to keep in mind:
- Respect the website's terms of service and robots.txt file
- Do not overload the website's servers with excessive requests
- Use the scraped data responsibly and in compliance with applicable laws
- Avoid scraping sensitive or proprietary information
There have been cases where companies have faced legal issues for scraping financial data without permission. For example, in 2019, a company called Compulife Software sued a competitor for allegedly scraping its insurance pricing data.
To stay on the safe side, consider reaching out to the website owner for permission or explore alternative data sources that explicitly allow web scraping. By being mindful of the legal aspects, you can ensure your web scraping activities remain ethical and compliant.
Save time and increase impact by using Bardeen's playbook to extract summaries and keywords, then store them in Google Sheets with one click.
Identifying Reliable Data Sources and Their Structure
To effectively scrape stock market data, you need to identify reliable sources that provide accurate and up-to-date information. Some popular and trustworthy websites for financial data include:
- Yahoo Finance
- Google Finance
- Investing.com
- Bloomberg
- Reuters
.png)
When choosing a data source, consider factors such as the website's reputation, data accuracy, update frequency, and the ease of scraping.
Once you've selected a source, inspect the website's HTML structure to locate the specific data points you want to extract, such as:
- Stock prices
- Trading volume
- Market capitalization
- Financial ratios
To examine the HTML structure, use your browser's developer tools:
- Right-click on the webpage and select "Inspect" or "Inspect Element"
- Navigate through the HTML elements to find the relevant data
- Look for specific tags, classes, or IDs that uniquely identify the data you need
.png)
Additionally, analyze the website's network requests to understand how data is loaded dynamically. This is particularly useful for websites that use JavaScript to fetch data asynchronously.
By carefully studying the website's structure and network requests, you can develop a targeted scraping strategy that efficiently extracts the required stock market data.
Automating Data Extraction and Handling Dynamic Content
When scraping stock market data, you may encounter websites that use JavaScript to dynamically load content. This can make extracting data more challenging, as the information may not be readily available in the initial HTML response.
To handle dynamic websites, you can use tools like Selenium or ScraperAPI:
- Selenium automates web browsers, allowing you to interact with JavaScript-rendered pages as if a user were navigating the site.
- ScraperAPI provides a proxy service that handles JavaScript rendering and CAPTCHAs, making it easier to scrape dynamic content.
Here's an example of using Selenium with Python to automate data extraction from a dynamic website:
- Install Selenium:
pip install selenium - Download the appropriate web driver for your browser (e.g., ChromeDriver for Google Chrome).
- Write Python code to initialize the web driver, navigate to the desired page, and locate the relevant data elements.
.png)
When dealing with pagination or multiple pages of data, you can automate the process of navigating through the pages and extracting data from each page. This may involve clicking on "Next" buttons or manipulating the URL parameters.
Additionally, consider handling session management and cookies to maintain a consistent browsing session throughout the scraping process. This can be crucial when scraping websites that require authentication or track user sessions.
By leveraging tools like Selenium and ScraperAPI, you can effectively automate the extraction of stock market data from dynamic websites, making your scraping process more robust and efficient.
Save time with Bardeen's scraper to automate data extraction from websites without code, letting you focus on more strategic tasks.
Identifying Reliable Data Sources and Their Structure
When scraping stock market data, it's crucial to choose reliable sources to ensure the accuracy and quality of the extracted information. Popular websites like Yahoo Finance and investing.com are well-known for providing comprehensive and up-to-date stock data.
To effectively scrape data from these sources, you need to understand their HTML structure. This involves inspecting the page elements and identifying the relevant data points, such as stock prices and trading volumes.
Here are some tips for examining the structure of financial websites:
- Use your browser's developer tools to inspect the page source and locate the HTML elements containing the desired data.
- Look for specific class names, IDs, or other attributes that uniquely identify the data points you want to extract.
- Analyze the network requests made by the website to see if the data is loaded dynamically through APIs or AJAX calls.
Once you have a clear understanding of the website's structure, you can use Python libraries like BeautifulSoup or lxml to parse the HTML and extract the relevant information.
It's important to note that some websites may have anti-scraping measures in place, such as rate limiting or IP blocking. Be sure to review the website's terms of service and robots.txt file to ensure compliance with their scraping policies.
By carefully selecting reliable data sources and studying their structure, you'll be well-equipped to scrape accurate and comprehensive stock market data using Python.
Storing and Utilizing Scraped Data Effectively
Once you have successfully scraped stock market data using Python, it's important to store the data in a structured format for easy analysis and reporting. There are several popular formats for storing scraped data, including CSV, JSON, and databases.
CSV (Comma-Separated Values) is a simple and widely supported file format that stores tabular data as plain text. Each line in a CSV file represents a row, with values separated by commas. Python provides built-in libraries, such as csv or pandas, for reading and writing CSV files effortlessly.
JSON (JavaScript Object Notation) is another common format for storing structured data. It is lightweight, human-readable, and easily parsable by programming languages. Python offers the json module for encoding and decoding JSON data.
Databases, such as SQLite, MySQL, or PostgreSQL, provide a more robust solution for storing and managing large amounts of scraped data. They allow efficient querying, indexing, and data manipulation using SQL (Structured Query Language). Python has libraries like SQLAlchemy that simplify database operations.
Before storing the scraped data, it's crucial to clean and format it properly. This involves removing any irrelevant or duplicate information, handling missing values, and ensuring consistent data types. Python libraries like pandas and NumPy offer powerful data manipulation and cleaning functionalities.
Once the data is stored in a structured format, you can leverage it for various purposes, such as:
- Performing basic stock market analysis, such as calculating average prices, trading volumes, or price changes over time.
- Visualizing the data using libraries like Matplotlib or Plotly to gain insights and identify trends.
- Integrating the scraped data into financial models or algorithms for further analysis and decision-making.
By storing and utilizing scraped stock market data effectively, you can unlock valuable insights, make informed investment decisions, and automate financial analysis tasks using Python.
Save time and increase impact by using Bardeen's playbook to extract data and store it in Coda with one click.
.png)
Automate Your Stock Data Analysis with Bardeen
Web scraping stock market data can significantly enhance your financial analysis, allowing you to gather and process vast amounts of data effortlessly. While manual methods exist, automating this process with Bardeen and its powerful Scraper integration can save you invaluable time and provide more accurate, real-time data for your analysis.
Here are examples of how Bardeen can automate the extraction of stock market data, making your financial analysis more efficient:
- Extract information from websites in Google Sheets using BardeenAI: This playbook automates the process of extracting key financial data from websites directly into Google Sheets, enabling real-time analysis and decision-making.
- Get data from the Google News page: Keep up with the latest market trends and news by automatically extracting summaries from Google News search results. This can provide valuable insights into market movements and investor sentiment.
- Get pricing information for company websites in Google Sheets using BardeenAI: This playbook is perfect for tracking stock prices or product pricing information directly from company websites into Google Sheets for comprehensive analysis.
By leveraging Bardeen's automation playbooks, you can streamline the collection of stock market data, allowing you to focus on analysis and strategy. Download and start using Bardeen today to transform your financial analysis process.

.svg)
.svg)
.svg)
